
自 2019 年起,让 AI 模型变得更强大的方法层出不穷。一种是使用更多训练数据,扩大模型规模;另一种则是针对什么是优质答案给出更精准的反馈。而在去年年底,谷歌和其他人工智能公司开始采用第三种方法——推理。
近日,谷歌发布首个混合推理模型 Gemini 2.5 Flash,该版本以 Gemini 2.0 Flash 为基础,在推理能力方面进行了重大升级,同时兼顾了速度和成本。
该模型引入了谷歌所谓的“思考预算”机制,允许开发人员指定在生成响应之前应分配多少计算能力用于推理复杂问题。有效解决了当今人工智能市场的一个根本矛盾:更复杂的推理通常以更高的延迟和更高的价格为代价。
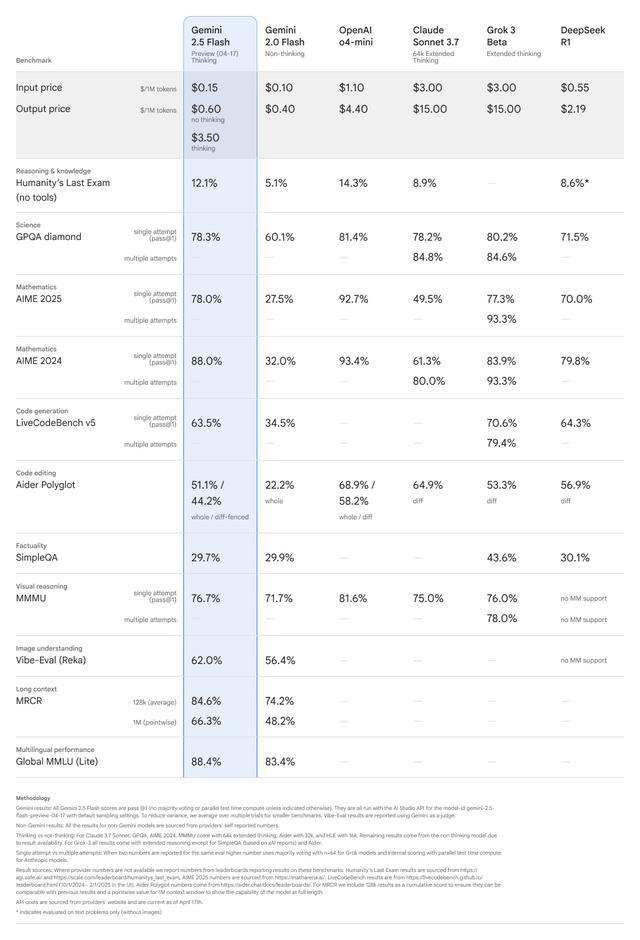
使用 Gemini 2.5 Flash 时,开发者每百万 token 的输入成本为 0.15 美元。输出成本则根据推理设置而存在显著差异:关闭思考功能时每百万 token 为 0.60 美元,而启用推理功能时则每百万 token 为 3.50 美元。
推理输出的近六倍价格差异反映了“思考”过程的计算强度,其中模型在生成响应之前会评估多种潜在路径和考虑因素。思考预算可以从 0 调整到 24,576 个 token,作为最大限制而非固定分配。据谷歌称,该模型会根据任务的复杂性智能地确定使用多少思考预算,从而在不需要复杂推理时节省资源。
谷歌声称,Gemini 2.5 Flash 在关键基准测试中展现出极具竞争力的性能,同时保持了比其他同类产品更小的模型规模。在“人类最后一次考试”(一项旨在评估推理和知识的严格测试)中,2.5 Flash 的得分为 12.1%,优于 Anthropic 的 Claude 3.7 Sonnet(8.9%)和DeepSeek R1(8.6%),但略低于 OpenAI 近期推出的 o4-mini(14.3%)。该模型在知识问答(GPQA)和数学(AIME 2025/2024)等技术基准上也取得了优异的成绩。
DeepMind 首席研究科学家 Jack Rae 表示:“我们一直在推动模型思考。”这类模型旨在通过逻辑推理解决问题,为得出答案会花费更多时间。随着 DeepSeek R1 模型在今年早些时候推出,推理模型受到了广泛关注。它们对人工智能公司颇具吸引力,因为通过训练现有模型以务实方式解决问题,能提升现有模型性能,公司也就无需从头构建新模型。
当 AI 模型在查询上投入更多时间和精力时,运行成本也会更高。推理模型排行榜显示,完成一项任务的成本可能高达 200 美元。人们期望这些额外投入的时间和资金,能帮助推理模型更好地应对诸如代码分析、从大量文档中收集信息等具有挑战性的任务。
Google DeepMind 首席技术官 Koray Kavukcuoglu 认为:“对某些假设和想法思考得越深入,模型就越有可能找到正确答案。”但事实并非总是如此。Gemini 产品团队负责人 Tulsee Doshi 指出,模型确实存在过度思考的问题,他特别提到了 Gemini Flash 2.5。此次发布的模型中包含一个滑块,开发人员可通过它调节模型的思考程度。
模型在一个问题上耗时过长,不仅会增加开发人员的运行成本,还会加重人工智能的环境负担。Hugging Face 的工程师 Nathan Habib 对推理模型的广泛应用进行了研究,他表示过度思考的现象十分普遍。他指出,在急于展示更智能的人工智能的热潮中,企业们不管什么情况都想用推理模型,就像手里拿着锤子,看什么都像钉子。实际上,OpenAI 在 2 月份宣布推出新模型时表示,这将是该公司最后一个非推理模型。
Habib 称,对于某些任务,推理模型的性能提升“有目共睹”,但对许多其他人工智能的普通用户而言并非如此。即便将推理应用于合适的问题,也可能出现状况。他提到一个例子,一个领先的推理模型在处理有机化学问题时,一开始表现尚可,但推理过程中却突然 “崩溃”:不断重复 “等等,但是……”。最终,它在这项任务上花费的时间远超非推理模型。在 DeepMind 负责评估双子座模型的 Kate Olszewska 也表示,谷歌的模型同样可能陷入循环。
谷歌推出的新“推理”滑块就是为了解决这一问题。目前,该功能并非面向 Gemini 的消费者版本,而是供开发应用程序的开发人员使用。开发人员可以为模型处理某个问题时设定计算能力预算,如果某项任务无需太多推理,就可以调低 “思考程度”。开启推理功能后,模型的输出成本大约会提高 6 倍。
设置这种灵活性的另一个原因是,目前还难以确定何时需要更多推理才能得到更好的答案。Jack Rae 表示:“很难界定什么样的任务最适合深度思考。”像编码(开发人员可能会将数百行代码粘贴到模型中寻求帮助)、生成专业研究报告这类任务,很明显需要深度思考,开发人员可能会调高“思考程度”,并认为为此付出的成本是值得的。不过,还需要进行更多测试并收集开发人员的反馈,才能确定在哪些情况下中低 “思考程度”的设置就足够了。
Habib 表示,对推理模型的巨额投资表明,提升模型性能的传统模式正在发生改变。他说:“规模定律正在被取代。”如今,企业们更倾向于认为,让模型思考更长时间,比单纯扩大模型规模能带来更好的效果。多年来,人工智能公司在推理(即模型实际生成答案时)上的投入明显高于模型训练,并且随着推理模型的兴起,这一支出还会加速增长。同时,推理过程产生的碳排放也越来越多。
即便推理模型持续占据主导地位,谷歌也并非一枝独秀。去年 12 月和今年 1 月,DeepSeek 发布的成果引发股市市值下跌,因为它宣称能以较低成本打造强大的推理模型。该模型被称为“开放权重”模型,也就是说,其内部设置(即权重)是公开的,开发人员无需付费使用谷歌或 OpenAI 的专有模型,就能自行运行。
那么,既然像 DeepSeek 这样的开放模型表现如此出色,为什么还有人选择使用谷歌的专有模型呢?Kavukcuoglu 表示,在编码、数学和金融领域,人们对模型的准确性和精确性要求极高,期望模型能理解复杂情况。他认为,无论是否开源,只要能满足这些要求的模型就能脱颖而出。在 DeepMind 看来,这种推理将成为未来人工智能模型的基础,这些模型将代表你行动,为你解决问题。
他还提到:“推理是构建智能的关键能力。模型开始推理的那一刻,就具备了一定的自主性。”
原文链接:
https://www.technologyreview.com/2025/04/17/1115375/a-google-gemini-model-now-has-a-dial-to-adjust-how-much-it-reasons/