
文|刘俊宏
编|王一粟
“AI大模型让我们看到自动驾驶,比任何时候都接近于落地。”
在中国汽车智驾能力竞争愈发激烈的今天,小鹏汽车自动驾驶副总裁李力耘找到了智驾通往自动驾驶的大门。
针对去年车企们热衷的端到端的智驾训练模式,李力耘认为智驾模型还能做得更大,要突破过去端到端模型的“一亩三分地”。
端到端的模型做智驾的好处,李力耘解释说,“用端到端的模型做自动驾驶,我觉得无非两个重要的点:一是保持信息的无损。另一个是降低整个车辆的延时,让自动驾驶的功能更加敏捷、高效和拟人。”
但直接学习人类行为的端到端,其上限只是接近人类。在大量的数据和训练中,智驾逐渐形成类似于人类日常驾驶的能力和习惯。但真正遇到极端场景时,智驾厂商几乎拿不到这部分数据。一方面是因为场景发生的频次非常少,另一方面是人类自己都反应不过来,根本就没有“可以参考的答案”。
如何让端到端智驾变得更强?小鹏给出的答案是用云端大模型蒸馏并辅以强化学习的方式,跳出之前车端思路做智驾模型的“一亩三分地”。
事实上,过往的自动驾驶其实并没有真正用到“大模型”。参考去年云端模型的进化,AI成长的基本逻辑,遵循Scaling Law的“规模越大,能力越大”。
“基于当前主流的车端芯片,车端模型的尺寸一般在1亿到5亿之间。最近非常受到业界关注的VLA模型,参数规模一般在20亿左右。这是因为自动驾驶的模型其实是一个非常复杂的,既需要兼顾视觉,也需要兼顾推理,最后还需要有动作输出的一个大模型。但是云端大模型可以真正突破这样的限制,整个参数量可以达到主流车端模型的35倍以上。”李力耘介绍道。
为了搭建云端足够强的大模型,本次小鹏首次披露了正在研发的720亿参数的超大规模自动驾驶大模型,即“小鹏世界基座模型”。
未来,小鹏将通过云端蒸馏小模型的方式将基模部署到车端,给“AI汽车”配备全新的大脑。
针对算力优化,小鹏从2024年开始搭建AI基础设施(AI Infra),当前已建立起万卡规模的智能算力集群,是目前国内汽车行业最大的自动驾驶算力集群。
如今,小鹏的算力储备达到10EFLOPS,集群利用率常年高达90%以上,高峰时期的运行效率甚至达到98%。
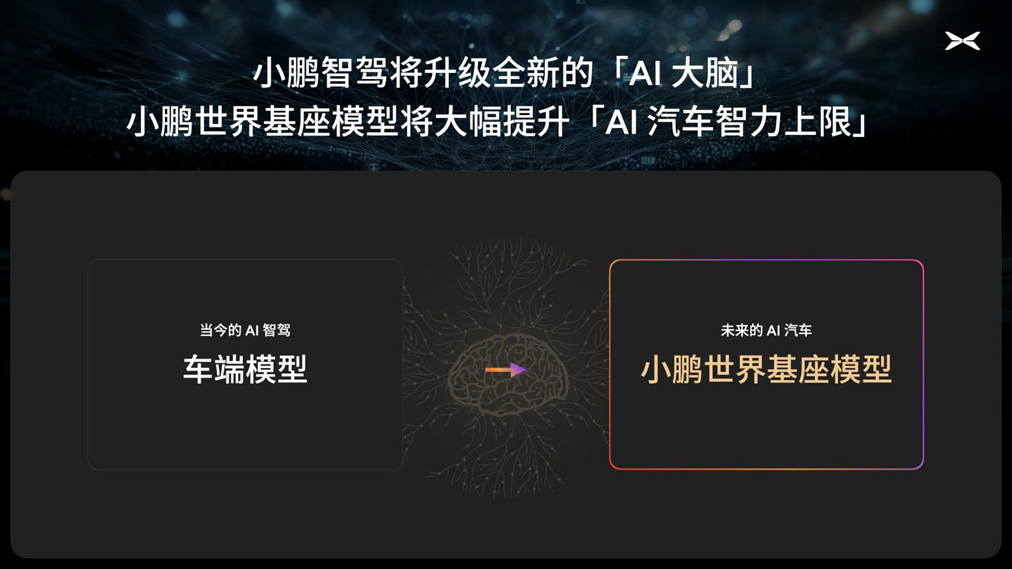
“我们为什么要投入巨大的资源去做云端的基座模型呢?如果我们只局限在车端算力的一亩三分地,我们模型大小是受限的,能真正消化的数据也是受限的。只有超越车端芯片算力的限制,真正用更大的模型、更海量的数据,去大道至简地把驾驶这件事做好,我们才能真正实现车端的智能。”李力耘介绍说。
如何让车端模型拥有云端大模型的能力?李力耘借用了去年云端模型的两个最重要的进化,“一个是知识的蒸馏,另一个是强化学习”。
Deepseek在数字世界证明了蒸馏和强化学习能够大幅增强大模型的能力,小鹏现在在具身物理世界尝试执行和落地。
其中,知识的蒸馏是先让云端大模型拥有深度思考(CoT思维链)的能力,然后再将这些能力蒸馏到车端模型上。在云端训练中,大模型形成对每一个场景会做出一系列符合逻辑,但又可能超越训练数据本身的思维链条。然后再将这些思维通过训练数据转化为操作,并以一个合适的频率操纵自动驾驶。
引入思维链之后,智驾大模型展现出了极强的泛化能力。“在香港其实我们并没有正式开放XNGP功能,但我们的用户发现在这里XNGP也可按照导航驾驶我们的车。说明了在真正大模型能力赋能下,通过蒸馏是可以期待自动驾驶真正具备自己的灵魂、自己的大脑的。”李力耘介绍说。
在蒸馏之后,接下来是利用强化学习来打破智驾大模型的上限,进而达到比人驾更安全的效果。在危急场景下,人类会紧张,会受到思维惯性的影响,但AI不会。针对AI强化学习,本质上就是允许AI利用一切操作,突破人类固有的认知,找到危险场景的可行解,从而最大化保障行车安全。
对于强化学习,根据小鹏世界基座模型负责人刘博士介绍,小鹏选择从三个方面入手搭建整个奖励机制。
首先是设计奖励函数。小鹏在这部分使用的是最简单的规则,例如合规、安全、舒适等,这些参数直接决定了行车体验。这些规则的设计和出发点,来自小鹏过往智驾研发过程中积累的大量经验。以这些规则作为大模型强化学习的开始,小鹏的智驾大模型在起步之初就打好了基础能力。
其次是设计奖励模型。奖励模型的设计目的,是让智驾模型获得更连续、更泛化、更多维的奖励信息。简单来说就是告诉智驾“什么是好的”,并以此让智驾想办法达成这些表现。这部分小鹏更重视智驾接管和市场的反馈数据,奖励模型就会让智驾尽量避免接管,或按照市场建议来改进“开车习惯”。
最后是世界模型。作为当前智驾最前沿的技术方案,行业内主要用世界模型来进行仿真,从而让端到端智驾持续获得泛化能力。在小鹏看来,世界模型不只是现实世界的“模拟器”。要想用好世界模型,就得将它作为智驾模型的闭环“训练场”。世界模型要有能力根据智驾模型的动作输入,模拟出真实的场景,并且生成其他智能体的响应,从而构建闭环的训练网络。
如何理解世界模型应该具有的能力?刘博士举了这样一个例子,假设智驾看到前面有辆车,随后选择了绕行。对过的车辆看见我们正在绕行,它也会稍微避开一点空间,而不是继续保持直行。世界模型本身的运行,应该符合常识,而非“生硬死板”的模拟空间。“世界模型更像是一个生成式的想象系统,要理解这个世界以及如何去完成动作”,刘博士总结说。
“在今天真的是非常幸运,在大模型的赋能下,我们真正看到自动驾驶离我们前所未有的近。”
回想起从事自动驾驶开发的经历,李力耘唏嘘不已。一路走来,小鹏汽车经历了硬件算力稀缺的时期,走过了不停写规则完善智驾的艰辛,也体验了端到端加速智驾研发的惊喜。面对自动驾驶的“高峰”,李力耘在研发中越来越有信心。
“功成不必在我,功成必定有我。我们小鹏汽车自动驾驶团队一定会在这条路上持续深耕,一定会把真正的自动驾驶带给大家。”
以下为小鹏AI大模型技术沟通会问答环节实录(经光锥智能编辑整理)。受访者为小鹏汽车自动驾驶副总裁李力耘与小鹏汽车自动驾驶产品高级总监袁婷婷。
Q:小鹏的AI模型开发与特斯拉有什么相同与不同?世界模型与其他友商有什么区别?
李力耘:我觉得应该是“英雄所见略同”。首先我们都是面向C端的公司,都有C端落地的产品,所以我们都有海量的数据。其次,我们都有非常高的算力储备和AI能力。我觉得很多东西可能就不言自明了,如果AI能力只是为了从车端训练小的模型的话,肯定不是一个终极方案。区别部分是小鹏的基座模型不仅仅是对世界的理解,更重要的是需要它像人一样大小脑兼并,可快可慢,进而实现与现实世界的交互。
袁婷婷:现在可能大部分人想要用世界模型做仿真,但很显然它不仅仅是只能做仿真。我们还在用模型来调教Agent(智能体)的反馈,和它之间的博弈以及接下来要做哪些动作。
Q:基于以往的规则,可以理解为是一种托底吗?世界模型生成的规则是否可能与以往设定的规则产生冲突?很多人都在提基座模型、VLA,看起来好像都是语言、视觉或者说动态的、多模态的概念,这些区别到底在哪里?
李力耘:我觉得最重要的区别是超越车端芯片算力的“一亩三分地”,我们的模型真的就是“大道至简”。不需要考虑部署的问题,就是先通过最简单的模型、最纯粹的模型架构、最海量的优质数据,达到超越的、未曾想到的能力涌现效果。
关于语言,语言是一种表征形式。不是说所有语言都应该以人类语言的形式表示。我们基于大语言模型加上独特的多模态视频编码器的输入,再加上我们动作解码器的输出,最后进行强化学习。我们的基座模型的目的,是为了做好物理世界交互。语言模型的预训练是一个起点,让模型有初步的推理能力,但更重要的还是让模型体现出推理和思维能力。在云端验证了这些能力之后,这才是我们值得去蒸馏的东西。
回到规则,在规则时代小鹏无疑是领先的,我们的规则积累很深。这些规则,以前可能算是一个负担,但现在非常自豪和高兴,因为这些规则正在转化成我们的资本。我们成功完成了很多核心研发同学从规则化到AI化的转型,尤其在强化学习的初期,规则其实算是积累好的经验和老师,规则不断沉淀,AI才能更高效地成长。没有以前规则的积累,可能会不知道如何去教AI。只有规则和强化学习的积累到一定程度,我们才能实现从Reward Model(奖励模型)到World Model(世界模型)的转变。
袁婷婷:我认为我们的云端的基座大模型和别人的云端训练至少有三处不同。
第一是我们的训练方式。我们在去年11月份就提出,先在云端训练一个非常巨大的模型,再蒸馏到车端的流程。今年1月我们看到DeepSeek公开的论文显示,他们也在用蒸馏方式时,我们感觉真的是英雄所见略同。通过这样的方式,可以突破车端模型的能力上限,改变云端参照车端算力来搭设模型规模的做法。
第二点是架构和性能表现不同。我们正在训练的模型已经达到了72B的参数。更大的模型能够支撑更大的训练数据量,我们现在用到的是2000万Clips,预计年底会达到2亿Clips。这些领先行业数量级的训练数据量,将转化成模型性能上的巨大优势。
第三点是我们的基础能力。我们从0开始建了AI Infra,这些AI基础设施不可能是一天忽然从0到1生成的。我们还建成了整个自动驾驶行业内首个万卡集群。如何把这些算力训练的效率发挥到最大化,以及如何12小时就能训练一版模型出来,这些都体现了我们今天领先于行业的一些特点。
Q:LLM的幻觉问题怎么解决,需要规则兜底吗?模型蒸馏到自研芯片上,其效率与使用常见芯片相比如何?
李力耘:确实大模型的预训上有时候会有一些幻觉或者偶尔有一些模态坍塌。这些情况很难针对出问题的case用类似写Loss-Function(损失函数)的方式解决。但我们通过后训练微调和强化学习进行打磨,最终目标是让AI不仅达到非常高的上限,而且还能对下限进行兜底。我们跟现在的车端端到端不一样,车端的端到端模型很小,有时候有一些东西确实很难学进去。但云端大模型是有能力掌握真正的灵魂和智能的,这是我们笃定的方向。
关于第二个问题。在云端的世界模型、仿真、实车验证了能力之后,是可以蒸馏到车端不同芯片上的。在确认云端的能力之后,车端的芯片决定了承载能力。我们希望用自研的芯片和软硬一体的优化给大家带来事半功倍的效果。
袁婷婷:我认为第二个问题关键就两点。第一是用蒸馏的方法一定能提高上限。所以,我们用云端的基座模型蒸馏到车端的方式,是远胜于现在直接训车端的双Orin或以后我们自己的芯片的。无论哪个都是加码,这是一个确定性的答案。
第二点,我们马上要发新车了。新的芯片算力一定比现在车端的算力有数倍提高。假设自动驾驶是一个人,需要有非常聪明的大脑、有非常锐利的眼睛,来面对这个世界并做出判断。这个过程中,最核心的部分一定是聪明的大脑。大脑越大,转的速度越快,一定更加厉害,我觉得这也是一个很简单的常识性问题。所以,无论是今天的双Orin车型还是来自研芯片的车型,都遵循ScalingLaw的进化。
Q:安全对汽车来讲是生命线,AI技术未来在安全中如何发挥更大的作用,在当下我们这套系统中我们有没有一些最新的思考?会再加一些规则或什么样的方式再去把控底线吗?
李力耘:我们认为安全最重要的是要有雪亮的眼睛,要有聪明的大脑,以及灵敏的身手和反应。安全作为我们最重要的一环,我们也在往这三个方向努力。
雪亮的眼睛,就是我们眼观六路,耳听八方,比如在传感器的覆盖上,我们是非常重视的。当然,更重要的是,我们认为你要有聪明的大脑,这样才能做到很多预防性的安全。最后,身手也需要好,无论是整个车端的端到端,还是通过云端的基座模型蒸馏出来的端到端,都是一体式的,所以会有最小的延时,使用最多的信息,以最敏捷的方法去帮我们把安全做到更好。
袁婷婷:第一,AI汽车一定是安全汽车。AI汽车一定代表了AI安全,这是确定性的,而且AI的安全在整个小鹏核心战略里是关键的,是决不会退让的一步。
第二,从端到端走向L3、L4的过程中,AI的第一步是端到端,它是极致人类行为的模拟。人类怎么开我就怎么开,可以和人类开得一样好,它显示出了你的舒适性、体验、灵活性都非常高。但要超越人类的时候,强化学习一定会带来新的惊喜。这也是为什么我们会用云端基座模型蒸馏的方式突破云端的上限,用强化学习既突破云端基座的上限,也突破车端的上限。
大家都非常担心AI的幻觉,担心下限守不住。首先,我想说我们现在可以看到的是随着AI介入越来越多,其实安全性的表现是越来越好的,而未来这个表现应该还会持续得更好,并且会远远超出人类现在驾驶行为能够带来的安全。所以会给大家超出预期外的安全,在更多的极限场景,如果你要达到L3、L4,就一定要在会遇到概率0.0001%的情况下也能够发挥出更好的实力。
Q:自研基座模型的必要性?为什么其他基座模型蒸馏的效果做不到小鹏这样?对模型开源有什么理解?
袁婷婷:其实大家首先需要LLM作为骨干,做自动驾驶就需要往上叠加大量现实世界数据。物理的AI世界非常复杂,跟文本的比特世界不一样。物理世界会遇到现实的速度、操控,人类、运动等非常不一样的状况。我们添加了自动驾驶数据以后,还用CoT推理链去一步步理解,推导出整个现实世界的脉络和物体的运动。这些都是区别,当然我们也有一个LLM的底层骨干网。
我认为小鹏自动驾驶也好、智能座舱也好,其实在AI开源浪潮中是受益的。无论是通义千问还是DeepSeek这些非常棒的、非常优秀的AI公司,都让我们有所受益,我们对未来的发展也抱着开放的态度。也许有一天大家也可以看到我们的自动驾驶有一部分也可以通过开放的方式,给世界和行业一些反馈,这也是我们对未来的期待,但今天肯定还没有到这个时候。